Archie | Conheça a história do primeiro buscador da internet
Por Alveni Lisboa • Editado por Douglas Ciriaco | •
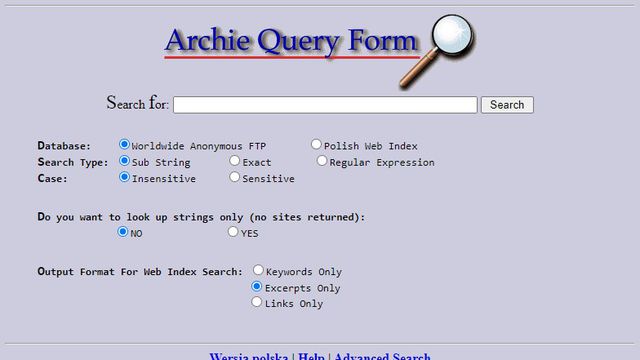
Se você acessou a internet na década de 1990, provavelmente vai lembrar com saudosismo do Cadê, do AltaVista e do persistente Yahoo!. Embora tenham sido muito populares no Brasil, outro buscador ganhou destaque no mundo por ter sido o primeiro da história. Seu nome é Archie e ele completa 30 anos no próximo dia 10.
Apesar da idade avançada, o Archi ainda continua no ar, embora apenas para registro histórico. Mesmo que seja um buscador, a pegada dele é diferente do que conhecemos hoje, com nomes como Google, Bing, DuckDuckGo: o objetivo do primeiro buscador da história era indexar e localizar arquivos FTP com mais facilidade.
O começo de tudo
O código original do Archie foi escrito em 1990 por Alan Emtage e Bill Heelan, estudantes de pós-graduação na Universidade McGill em Montreal, no Canadá. A dupla desenvolveu um script que permitia o login de usuário e a pesquisa no host archie.mcgill.ca [132.206.2.3], que continha uma listagem de arquivos.
A terminologia escolhida deriva da palavra “arquivo” (archive, em inglês), na qual foi retirada apenas uma letra para manter a sonoridade. Isso faz mais sentido do que uma teoria da época que fazia a associação com as histórias em quadrinhos de mesmo nome — as quais o criador dizia detestar. Apesar disso, essa confusão fez com que os sucessores do Archie recebessem nomes de personagens de quadrinhos: Jughead e Veronica.
Neste começo, o serviço de pesquisas tratava-se de um projeto para ajudar alunos e funcionários da Escola de Computação da universidade a encontrar arquivos no servidor via internet. Lembre-se que no início da década de 1990 as interfaces gráficas ainda eram novidade e não existia internet liberada para o público, por isso um mecanismo de busca era um conceito que não havia sido criado.
Como o Archie funcionava
Naquela época, a única forma de subir sites para a internet era por meio do File Transfer Protocol (FTP). As páginas eram criadas nos aplicativos de design da época e depois um upload era feito para as hospedagens de modo bem arcaico, com a incrível velocidade dá época, que não passava dos 28kbps.
A única forma de acessar essa rede de pesquisas era com um cliente local, que tinha o mesmo nome do buscador. Depois de algum tempo, foi inserida a possibilidade de se acessar o servidor diretamente por outros sistemas, consultas por e-mail e, finalmente, uma interface liberada na World Wide Web.
O buscador fazia uma varredura em uma lista de sites públicos hospedados em servidores FTP vinculados à rede mundial de computadores. Toda vez que uma página era atualizada, era necessário atualizar essa listagem, chamada "índice", mas isso só ocorria de tempos em tempos para não desperdiçar recursos dos servidores. Assim, as páginas podiam demorar até meses para serem colocadas online, já que as pessoas deixavam juntar uma quantidade mínima delas para fazer tudo de uma vez.
A busca era feita pelo título do arquivo armazenado no banco de dados, porque o sistema não identificava o conteúdo. Também não existiam descrições nem outros metadados que ajudassem na indexação. Se você não soubesse exatamente o nome do site que procurava, a chance de localizá-lo era zero.
Evolução para se parecer com o modelo atual
Em 1992, os jovens conseguiram apoio financeiro da Universidade McGill para criar a Bunyip Information Systems, a primeira empresa do mundo dedicada a fornecer serviços de informação na Internet. Foi essa companhia a responsável por tirar o Archie do ambiente acadêmico e levá-lo para o mundo comercial.
O sucesso do buscador fez com que o negócio crescesse e surgisse o Archie Group. Com novos sócios e um foco para o mercado, o banco de dados foi atualizado para conter muito mais arquivos e páginas da web.
Em 1993, o mecanismo de busca estava bastante ativo e tinha cerca de 50 mil consultas por dia de usuários em todo o mundo. Isso fez com que os criadores do projeto precisassem de uma dúzia de servidores para replicar um banco de dados de 150 MB, em constante evolução e com cerca de 2,1 milhões de registros. O resultado da busca poderia variar de alguns segundos em uma noite de sábado a até várias horas durante uma tarde normal de um dia de semana.
Embora não fosse um buscador como se conhece hoje, é inegável a importância do modelo criado pelo Archie, pois ele virou inspiração para os sistemas que o sucederam — notadamente o Yahoo!, em 1995, e o Google, em 1997.
Atualmente, um servidor Archie ainda é mantido ativo na Polônia, no Centro Interdisciplinar de Modelagem Matemática e Computacional da Universidade de Varsóvia, como uma forma de manter viva a memória do primeiro buscador da web. Você pode dar uma passadinha por lá e tentar reviver como as pessoas procuravam por coisas na internet no começo da década de 1990.
Fonte: Archie, HuffingtonPost, StackScale